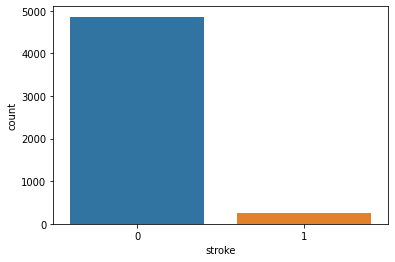Stroke Patients Analysis And Classification
The project includes analysis of stroke patients dataset and creating classification models for categorizing patients into stroke patients and no-stroke patients.
The project is divided into three stages EDA, Visualization and Modeling ,while in last part I share my thoughts. The data for the project was taken from Kaagle.
1. EDA
- In this stage, data was analysed to see if there are any null values, data inconsistencies etc. and get rid of it.
- Only 'BMI' column contained null values which were replaced with mean BMI to maintain the distribution.
- Column 'gender' had only one value Other, which was replaced with Male value based on values of other features.
- Also, distribution of data and some basic relationships were visualized to understand the data better.
2. Visualization
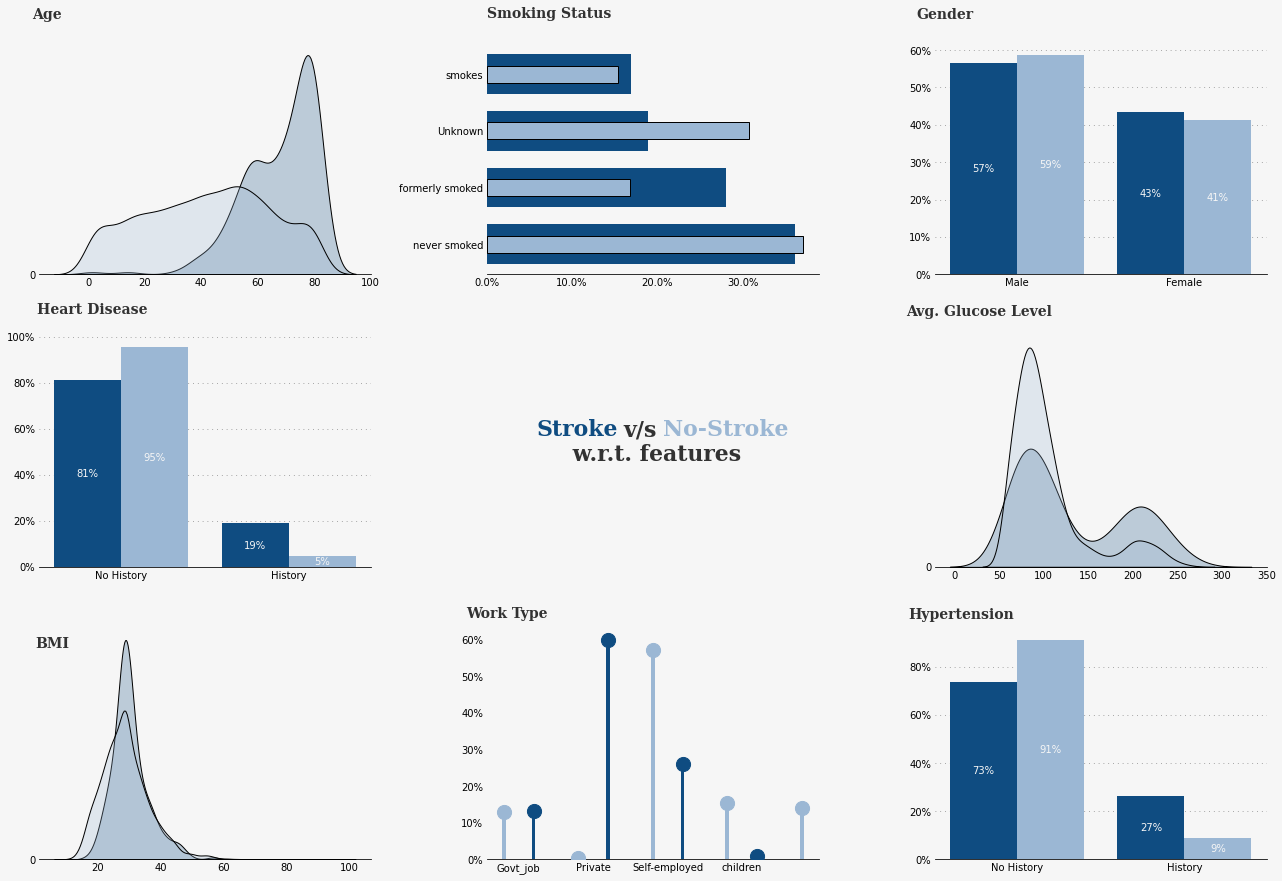
- The new data created from the visualization was used to create a responsive dashboard to compare or analyse patients with respect to lifestyle health features provided in data.
- Some numerical variables were converted in categorical groups for better categorising.
- Some new measures were created using DAX to help with visualization and understanding of patients stats better.
3. Modeling
- The data was preprocessed in the stage with handling categorical variables, Scaling the data etc.
- The target variable 'stroke' contained heavy imbalance between the categories. The imbalanced was removed using SMOTE.
- 6 classification models using Decision Tree, KNN, Logistic Regression, Random Forest, SVC, XGBoost were created.
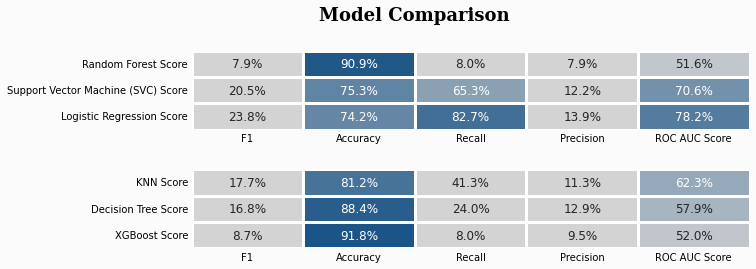
- The performance was analysed for individual classifier and the best model was selected using hyperparameter tuning.
- The best model of each classifier was trained and tested on the data and metrics scores were recorded and stored for final comparison and conclusion.
- The model should be selected based on domain knowledge as the evaluation criteria might change.
4. Conclusion
- The original data was heavily imbalanced, which affected the result significantly. Using SMOTE improved results slightly which os still good.
- Regarding Evaluation criteria, In healthcare domain, recall is as important as accuracy, because we want more patients to get treated while avoiding unnecessary treatment for healthy people.
- The situation demands balanced evaluation between accuracy and recall, which makes 'f1-score with recall score' most valuable metric.
- Based on above metric, I recommend Logistic Regression. Even though it lacks a little in terms Accuracy. The recall score, f1 score and ROC-AUC score makes it suitable candidate for me. But, it just my opinion.
- As I mentioned earlier, domain experts can have different opinion depending how they want to handle the problem.