Analysing Tuberculosis Cases in Kaduna State(Nigeria) 2019-2023
This project was part of colab between Omdena and Kaduna Local Authorities. About 15-20 people were working on the project at different stages of Data Collection, EDA, Visualization, Modeling, Deployment And Presentation. Here is the final result of approx. 3 months of hardwork and teamwork.
I was mainly part of EDA and Visualization team although I wanted to be involved in all phases. The data collected was divided into blocks where I worked on Block2C. The contents of the blocks were slightly different from each other, so is the focus of Analysis.
1. EDA
For starting phase, The data was separated in years[for each block],So separate analysis for each year 2021,2022,first_half-2023 and then combined analysis for whole period was done.
At later stages, the new data was added from 2019,2020 and second_half-2023. The EDA for combined period of 2019-2023 was performed.
This phase involved analysing inconsistencies like null values, outliers,data_types and data_values etc. as well as analysing distributions of the data. Using Python and Plotly the task was completed very effectively.
Because of the amazing work of the data preprocessing team and simplicity of data there were no major challenges. But few minor as challenges mentioned below -
- Few Null values were present which were imputed with zero.
- The names of LGAs were slightly different from references which were corrected.
- The data format for columns "LGA" and "Age_Gr" for 2021 were different from that of 2022 and 2023, so for combined EDA changes data was replaced in 2021 to maintain consistency.
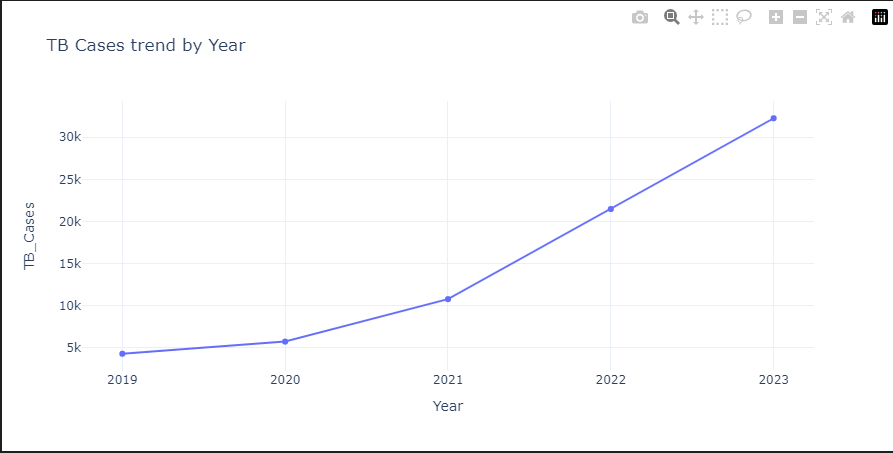
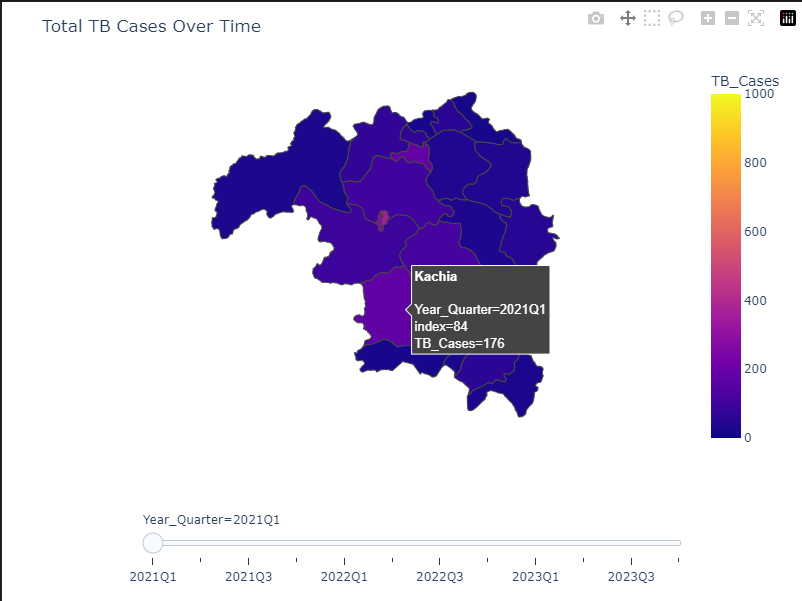
Here are some of the findings from the Block2C_EDA_updated.
2. Visualization
Plotly was used during this phase to showcase trends and insights related to TB Cases w.r.t different demographics.3. Modeling
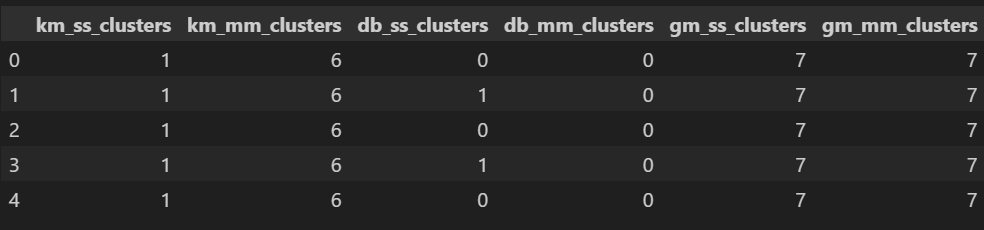
Although could not be part of modeling team, I tried to create clustring based model for the data using K-means, DBSCAN, Gaussian Mixtures algoritms. The data was scaled using both StandardScaler and MinMaxScaler. Elbow Method was used for finding Optimal K in KMeans. K-distance Graph was used for finding Optimal eps values in DBSCAN. AIC and BIC score were used for finding n_components in Gaussian Mixtures. Total 8 clusters were formed based on evaluations. The Silhouette Score was used as a metric for performance evaluations. Silhouette score for final models were:- KMeans: 0.4121
- DBSCAN: 0.4121
- GMM: 0.4377