Predicting Sales of Different Products of Big Mart using Regression
The project is about predicting Sales of different products from different Big Mart Outlets.
The project was divided into two parts understanding the dataset [EDA] and analysing performance of different Regression models on the data.
1. EDA
- This stage involved understanding the data and getting rid of the unwanted things.
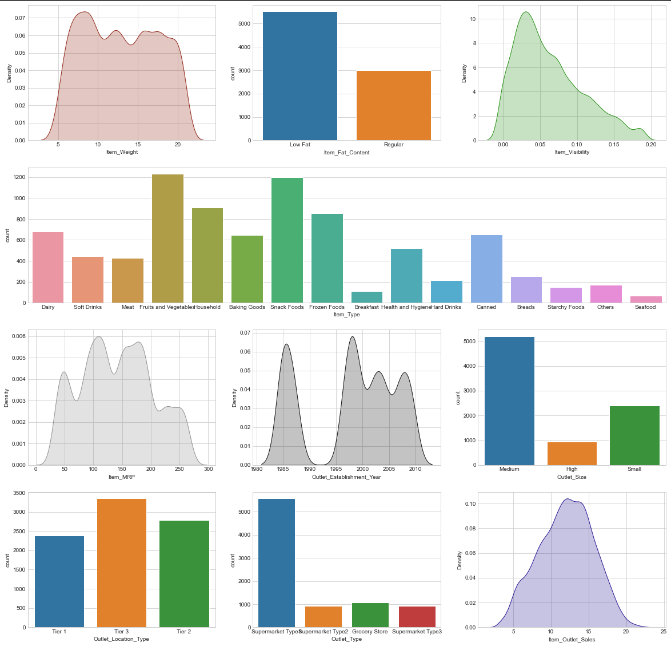
- Columns 'Item_weight' and 'Outlet_Type' had missing values. For Column 'Item_weight' the missing values were replaced with weight of same products from different outlets if it was available. For column 'Outlet_Type' the null values were replaced with mode of data. The null values still remained were dropped.
- The data was inconsistent in column 'Item_Fat_Content' i.e. same values were present in different format which were replace with one consistent value
- The data in columns 'Item_Visisbility' and 'Item_Outlet_Sales' were skewed which were converted to normal distribution using log-transformation and cuberoot-transformation resp.
- Columns 'Item_Visibility' and 'Item_Outlet_Sales' had outliers which were handled using IQR method.
- The data was visualised using different graphs using matplotlib and seaborn.
2. Model Building
- For first step, the unwanted columns like index and identifiers were dropped.
- The categorical columns were encoded using pandas get_dummies and Label Encoder.
- The numerical columns were scaled down using StandardScaler as Regression models are sensitive to range of data.
- Different regression models like Linear Regression, Random Forest Regression, Support Vector Regression and XGBoost Regression etc. were evaluated with cross_validation and hyperparameters against the data.
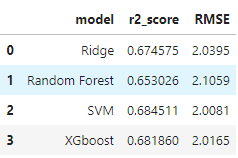
- R2_score and Mean_Absolute_Error was used for individual evaluation while R2_score and Root_Mean_Squared_Error were metrics for final evaluation.
3. Conclusion
- Based on evaluation, SVM seems to performed well while XGBoost can also be a choice as it is close to SVM. Overall performance of models is above average but not good.
- With more in-depth modelling like feature selection, more hyperparameter tuning, improved performance can be achieved.